
Guidelines to get you started with the art of finetuning!
Dataset Requirements
Before configuring your training parameters, ensure you upload a clean dataset in CSV format with proper column names. The dataset should be well-structured and free from errors. A high-quality dataset is crucial for effective fine-tuning of the LLM.
Training parameters of LLM models
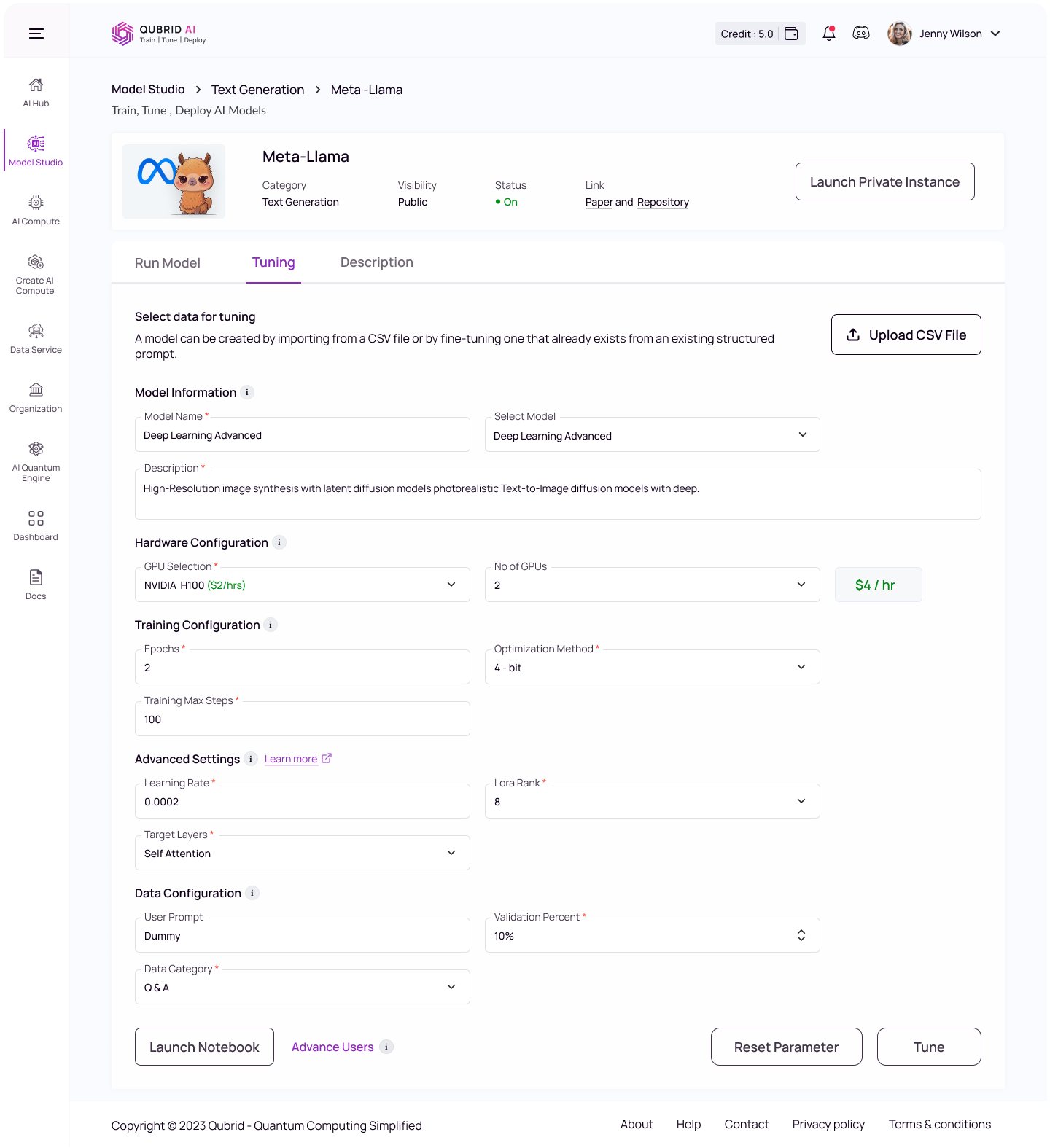
Model Information
- Model Name: Enter a name for your fine-tuned model.
- Select Model: Choose a base model used for training.
- Description (Optional): Provide a brief description of the model’s purpose, task, or dataset.
Hardware Configuration
- GPU Selection: Select the type of GPU to use for model training. Example:- A10 G, L4 etc.
- Higher-end GPUs (e.g., A100, V100) reduce training time, while less powerful GPUs (e.g., A10, L4) can lead to longer training and slower convergence.
- No of GPUs (NA): Specify the number of GPUs to allocate for training.
- Using multiple GPUs allows for distributed training and larger datasets but requires careful setup to manage synchronization.
Training Configuration
- Epochs: Total number of training epochs to perform (if not an integer, will perform the decimal part percent’s of the last epoch before stopping training).
- Training for more epochs gives the model more opportunities to learn from the data.
- This can improve the model’s performance, but too many epochs may lead to overfitting, where the model performs well on training data but poorly on new, unseen data.
- Optimization Method: Select the model optimization method (e.g., 4-bit or 8-bit).
- The default is set to 4-bit for efficient training.
- However, this might slightly compromise model performance, as it allows the model to fit in lower memory.
- Training Max Steps: Higher max steps improves performance by allowing more iterations, but may lead to overfitting. Fewer steps reduce overfitting risk but can result in under-training, especially with complex tasks or limited data.
Advanced Settings
- Learning Rate: Specify the rate at which the model adjusts its weights during training (default = 2e-4).
- A higher learning rate speeds up training but risks instability and poor performance, while a lower rate provides more stability but can lead to slower training.
- LoRA Rank: Set the rank for Low-Rank Adaptation (LoRA) to optimize the efficiency of fine-tuning (default = 32).
- A higher rank boosts model flexibility and performance but requires more resources, while a lower rank limits adaptability but improves efficiency, making it ideal for simpler tasks.
- Target Layers: Select the specific layers of the model to apply fine-tuning or LoRA adjustments (default = all ‘self-attn’ modules).
- Fine-tuning all layers enhances model learning and task adaptation but demands more computational resources and longer training. In contrast, focusing on fewer layers reduces training time and resource needs but may limit the model’s ability to learn complex patterns.
Data Configuration
- User Prompt (Optional): Provide the text or instruction prompt for the model to learn during training.
- Validation Percent: Specify the percentage of data to reserve for validation during training (default = 20%).
- Data Category: Select the type or category of data used for training the model. For Question Answering (qa), use a format with questions and their respective answers as two separate columns in a CSV file. For Non Question Answering (not-qa), provide any other content in the CSV file.
Important Note on Model Performance
Please note that the results of the fine-tuned model depend on the training parameters you select. You can improve the results by retraining the model with adjusted parameters.