
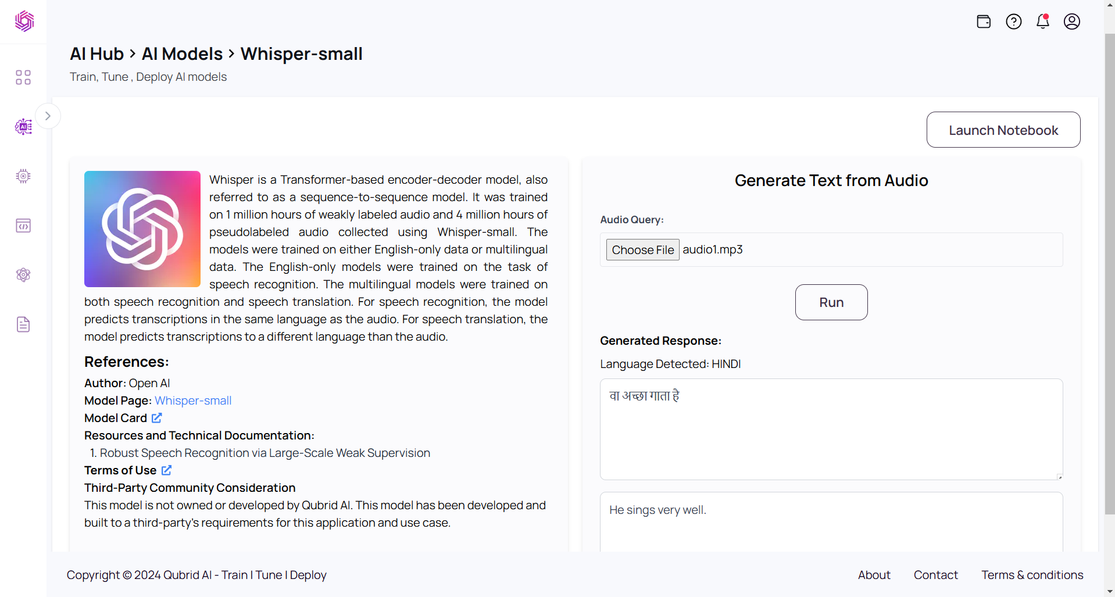
In this blog, we provide a comprehensive tutorial on fine-tuning the Whisper model for multilingual automatic speech recognition (ASR) using the Qubrid AI Platform. The platform features an AI Hub with various models, including Whisper, where users can upload audio files and receive transcriptions, translations and language detection results for free. This guide will explain the Whisper model, the Common Voice dataset, and the theory behind fine-tuning, complete with code examples for data preparation and fine-tuning steps. For those interested in fine-tuning the model, you can access the fine-tuning notebook directly from the platform. For a more detailed guide on navigating the Qubrid AI Platform, check out the Qubrid Platform Getting Started Guide.
Introduction
Whisper is a pre-trained model for automatic speech recognition (ASR) published in September 2022 by the authors Alec Radford et al. from OpenAI. Unlike many of its predecessors, such as Wav2Vec 2.0, which are pre-trained on un-labelled audio data, Whisper is pre-trained on a vast quantity of labelled audio-transcription data, 680,000 hours to be precise. This is an order of magnitude more data than the un-labelled audio data used to train Wav2Vec 2.0 (60,000 hours). What is more, 117,000 hours of this pre-training data is multilingual ASR data. This results in checkpoints that can be applied to over 96 languages, many of which are considered low-resource.
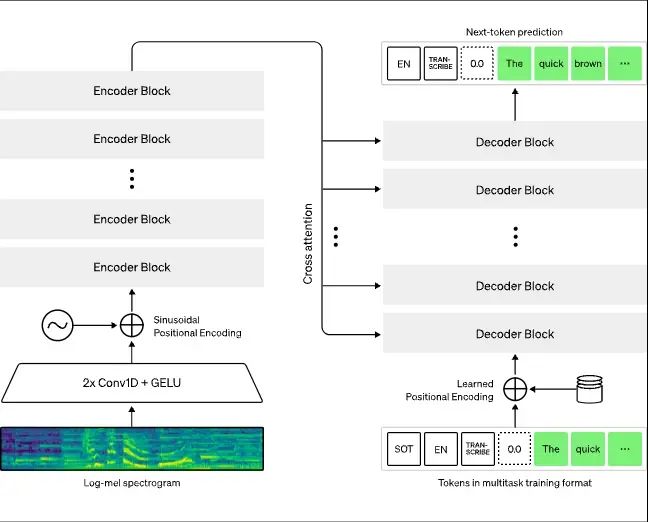
Whisper is a Transformer based encoder-decoder model, also referred to as a sequence-to-sequence model. It maps a sequence of audio spectrogram features to a sequence of text tokens. First, the raw audio inputs are converted to a log-Mel spectrogram by action of the feature extractor. The Transformer encoder then encodes the spectrogram to form a sequence of encoder hidden states. Finally, the decoder autoregressively predicts text tokens, conditional on both the previous tokens and the encoder hidden states. Figure 2 summarizes the Whisper model.
Fine-Tune Whisper in Jupyter Notebook on the Qubrid AI Platform
After launching the notebook on the Qubrid Platform, you will be presented with a JupyterLab environment equipped with several essential tools and resources to facilitate the fine-tuning process.
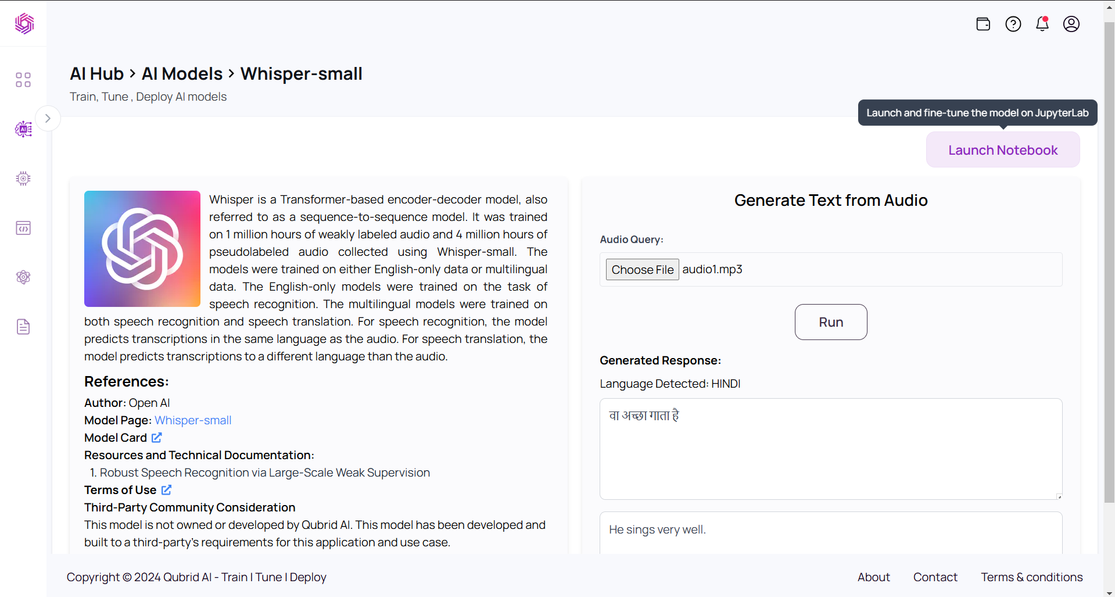
Here’s what you will find inside Jupyter Lab:
- GPU for Training
- Pre-Trained Model
- Fine-Tuning Sample Notebook
- Pre-requisite Packages
By providing these tools and resources, the Qubrid AI Platform simplifies the process of fine-tuning the Whisper model, allowing you to focus on optimizing the model’s performance for your multilingual ASR needs. Figure 3 shows what the fine-tuning notebook looks like when launched on the Qubrid AI platform.
- Verify that you have a GPU for training the Whisper model
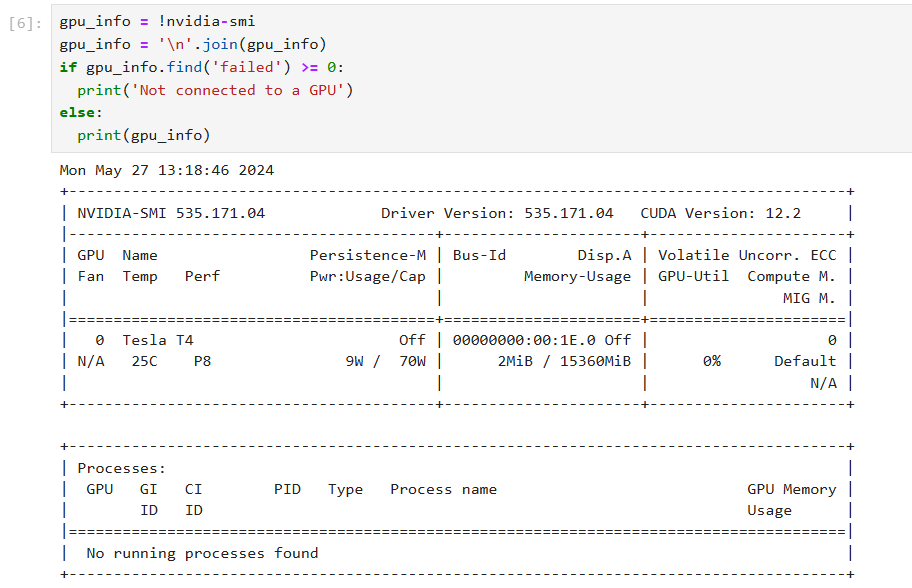
Ensure that your instance includes a GPU, which is crucial for efficiently training the Whisper model and significantly speeding up the fine-tuning process.
On the Qubrid AI Platform, you can access various types of GPUs such as T4, A10, L4, and more, making it suitable for training different AI models.
- Install the pre-requisite packages saved in the
requirements.txtfile.
Providing these pre-requisite packages directly to the user ensures a smooth setup process, allowing the environment to be ready for fine-tuning without additional configuration.
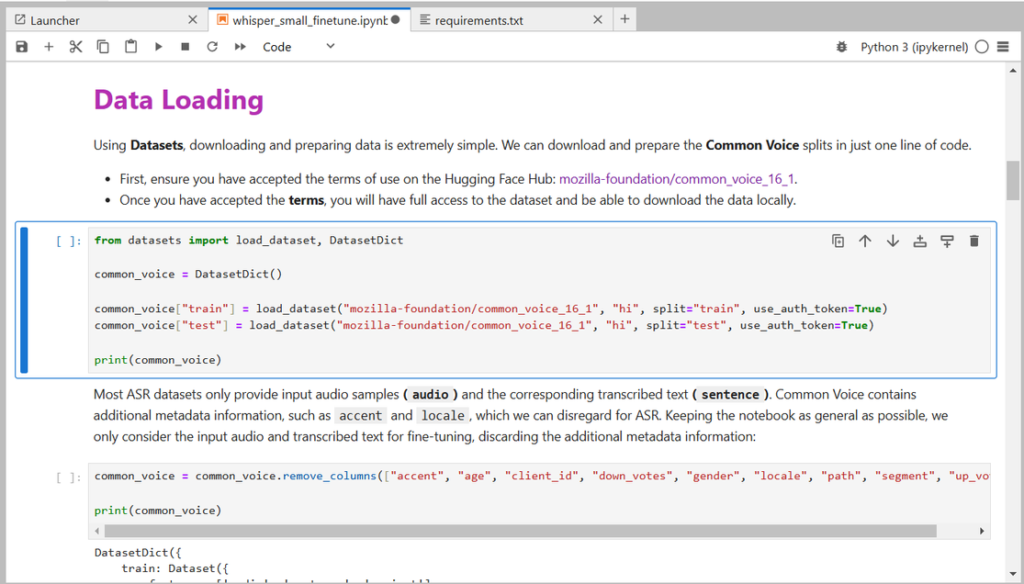
- Loading the Dataset
For fine-tuning the Whisper model, we will use the Common Voice dataset provided by the Mozilla Foundation. To access this dataset, you need to enable access through Hugging Face. This will allow you to seamlessly load and use the dataset for your training process.
Currently, we are using the Hindi language dataset, but you can select any language according to your task as Common Voice supports multilingual datasets for many languages.
- Preparing the Whisper Model and Tools
In this step, we will load the essential components required for fine-tuning the Whisper model: the Whisper feature extractor, Whisper tokenizer, and the evaluation metric, which is Word Error Rate (WER). Additionally, we will load the Whisper model itself.
The Whisper feature extractor is responsible for processing the audio data into a format suitable for the model, while the Whisper tokenizer converts text into tokens that the model can understand. The evaluation metric, WER, is crucial for assessing the performance of the model by measuring the accuracy of the transcriptions. Finally, loading the Whisper model prepares it for the fine-tuning process, allowing us to adapt it to our multilingual ASR dataset.
All these steps are covered in the fine-tuning notebook. Access the notebook and the Whisper model here.
5. Defining the Training Configuration
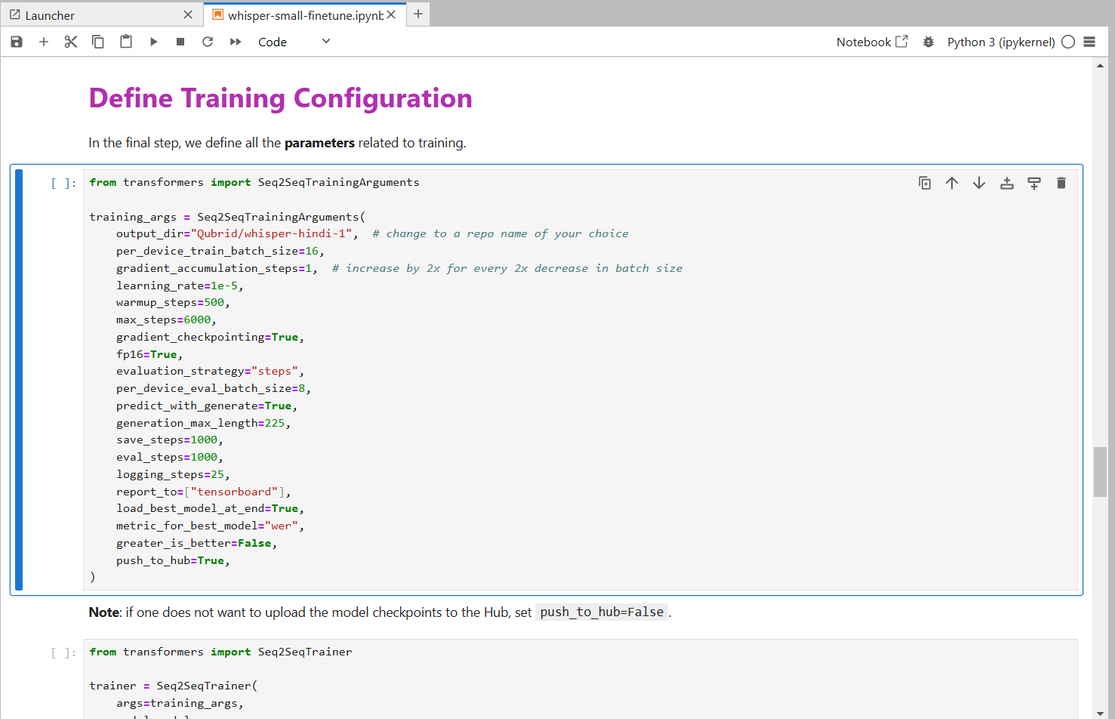
- Model Training and Results
Training will take approximately 5-10 hours depending on your GPU. Depending on your GPU, you might encounter a CUDA “out-of-memory” error when starting the training. If this happens, try reducing the per_device_train_batch_size incrementally by factors of 2 and use gradient_accumulation_steps to compensate.
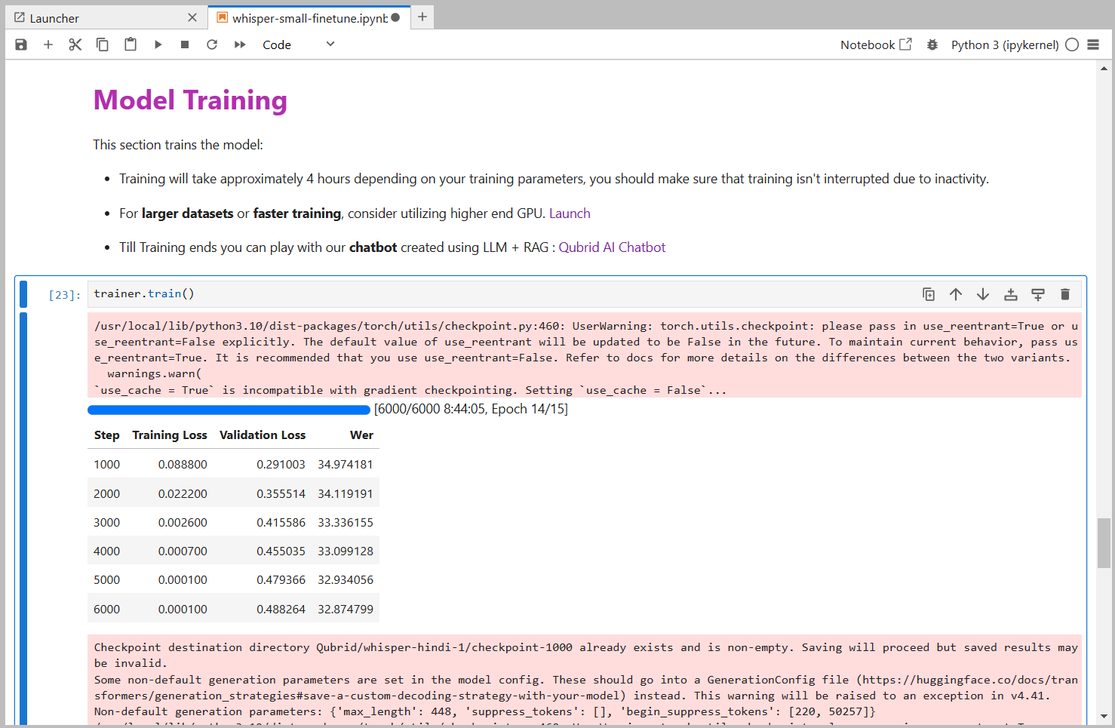
Our best WER is 32.87% after 6000 training steps. For reference, the pre-trained Whisper small model achieves a WER of 63.5%, meaning we achieve an improvement of 30.7% absolute through fine-tuning. Not bad for just 8h of training data!
We can make our model more accessible on the Hub with appropriate tags and README information. You can change these values to match your dataset, language and model name accordingly.
Closing Remarks
In this blog, we covered a step-by-step guide on fine-tuning Whisper for multilingual ASR using Qubrid AI Platform. If you’re interested in fine-tuning other AI models, like LLM or Text-2-Image be sure to sign in and check out the Qubrid AI Hub .