

What is Qubrid AI Secure & Scalable NVIDIA H200 GPU Server Appliance?
Most AI cloud solutions are great for testing new models quickly or doing proof of concepts and in some cases going to production. However if your AI data is critical and you want a secure way to deploy AI applications with new AI models originating from different parts of the globe, you need a secure Qubrid AI appliance deployed on your premises and in your data center behind your private or air-gapped network. The QAI-LLM-8SH200 is not just a server with an operating system. Powered by powerful NVIDIA H200 141GB GPUs, this plug and play appliance comes with Qubrid AI’s AI Controller SW which allows you to get started quickly with AI and perform ongoing management of AI users, AI infrastructure and helps you and your IT or AI Admin with a set of tools that simplifies their lives and saves cost and effort for complex AI tasks. All you need to do is to power and boot into the system and accelerate your AI projects without going through manual setup, management and operations of your AI infrastructure and tools.
Using the AI Controller software, you can add as many nodes as you want and manage hundreds or thousands of GPUs under one management interface.
Simplified AI Systems & Datacenter Management: Empowering AI & IT Admins
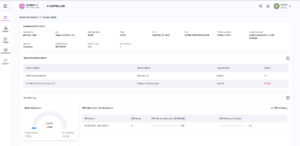
By streamlining datacenter management, simplifying developer resource allocation, and offering comprehensive GPU control, the Qubrid AI On-Premise GPU Management & System Controller empowers IT administrators to optimize their infrastructure for maximum efficiency and productivity. Below is a quick snapshot of our software. For full demo, please schedule:
- Single Pane of Glass: Effortlessly manage all GPU servers across your datacenters from a centralized console.
- Automated Deployment: Deploy GPU clusters with a few clicks, streamlining your infrastructure setup.
- Centralized Updates: Maintain consistent and up-to-date systems across your datacenter with a user-friendly interface.
- Seamless Updates: Effortlessly update operating systems, GPU drivers, Python versions, and common packages across all servers.
- Developer-Centric Resource Management:
- Flexible Container Provisioning: Provision tailored compute containers for individual developers, ensuring consistent IT standards and customization options.
- Resource Allocation Control: Allocate compute and GPU resources to developers based on their needs, eliminating resource contention and maximizing utilization.
- Advanced GPU Management:
- Fine-Grained Control: Create GPU compute resources ranging from individual GPU fractions to clusters with multiple GPUs.
- Comprehensive Monitoring: Track GPU and system resource usage across multiple nodes, gaining valuable insights into performance and resource utilization.
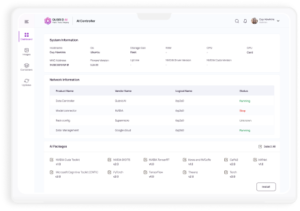
- Unified GPU Management: Manage diverse GPU types (e.g., NVIDIA H200, H100, A100, L40S, RTX 6000 ADA etc) from a single console, simplifying operations and reducing complexity.
Open Source AI Models out of the Box
 Manage your interactions with popular AI models with intuitive user interfaces.
Manage your interactions with popular AI models with intuitive user interfaces.
- Library of published Open-Source AI Models for tuning and inferencing available on-demand
- Fine-tune AI models on your local GPU server or scale across thousands of GPUs
NVIDIA NIM Microservices Integrated
 Part of NVIDIA AI Enterprise, NVIDIA NIM is a set of easy-to-use inference microservices for accelerating the deployment of foundation models on any cloud or data center and helping to keep your data secure.
Part of NVIDIA AI Enterprise, NVIDIA NIM is a set of easy-to-use inference microservices for accelerating the deployment of foundation models on any cloud or data center and helping to keep your data secure.
- Fully Integrated NVIDIA Enterprise catalog (NIM, CUDA, Nemo, etc.)
- Note – NVIDIA NIM requires separate Enterprise AI license – please contact us for more info.
Easily Deploy Hugging Face AI Models On Your GPU Appliance
 The Qubrid AI Controller software allows you to easily deploy AI models of your choice from the Hugging Face repository. Simply enter the AI model ID, select number of GPUs and deploy the model. You can then do inferencing on these models on any GPU node in your infrastructure. Qubrid AI offers you the choice of curated open-source AI models, NVIDIA optimized NIM catalog or selection from thousands of models on Hugging Face – all deployable and manageable from the same software.
The Qubrid AI Controller software allows you to easily deploy AI models of your choice from the Hugging Face repository. Simply enter the AI model ID, select number of GPUs and deploy the model. You can then do inferencing on these models on any GPU node in your infrastructure. Qubrid AI offers you the choice of curated open-source AI models, NVIDIA optimized NIM catalog or selection from thousands of models on Hugging Face – all deployable and manageable from the same software.
No-Code Fine-Tuning and RAG
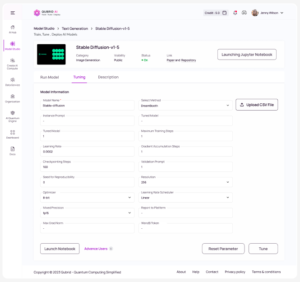 Fine-tuning an AI model does not have to be hard. With our AI appliances, you don’t have to be a programmer or data scientist to fine-tune a model. same for RAG – just upload your departmental data and hit a button to take advantage of close to real-time RAG capabilities.
Fine-tuning an AI model does not have to be hard. With our AI appliances, you don’t have to be a programmer or data scientist to fine-tune a model. same for RAG – just upload your departmental data and hit a button to take advantage of close to real-time RAG capabilities.
- Simple no-code fine tuning and RAG but with ability for advanced coding in Jupyter notebook
- Name your fine-tune model and save as templates
- Input multiple data types such as pdf files, images etc with a push of a button
Deep Learning & Machine Learning Packages Included
 No more headaches of managing AI packages. Even with factory loaded packages, it is hard to manage and update these packages manually. The AI Controller automates that for you.
No more headaches of managing AI packages. Even with factory loaded packages, it is hard to manage and update these packages manually. The AI Controller automates that for you.
- One touch deployment of complete AI/ML Deep Learning packages (PyTorch, TensorFlow, Keras, etc.)
- Automated install and update for your discovery and research needs
- Continuous addition of new open-source tools
Hardware Specifications
This appliance is built using NVIDIA’s H200 GPU. Below are complete specifications:
- Supermicro HGX Server
- 8U Rackmount form-factor
- 8 x NVIDIA H200 141GB HGX NVLink Inter-connected GPU
- Total 1128GB HBM3e Memory – 5th Generation NVLink
- 2 x 96-core CPU
- 2TB of ECC Registered Memory
- 8 x 3.8TB NVMe 2.5” SSD
- 8 x 2-port 200Gb Network Ports (or 8 x 1-port 400Gb Network Ports)
- Qubrid AI Controller Software
The server hardware specifications are customizable. Please contact us for custom configuration.
World Class Hardware, Software and AI Support
This appliance comes default with our comprehensive 3-year next-day onsite hardware assistance, ensuring your systems remain operational and efficient. Additionally, our dedicated AI support covers everything from AI model consulting to CUDA help and fine-tuning assistance, providing you with the expertise you need to maximize your AI technology investments. With our commitment to customer satisfaction, you can rest assured that help is just a call or email away, every step of the way.




