GLM-5.1: Next-Generation Agentic Engineering Model
GLM-5.1 is Z.ai's next-generation flagship model purpose-built for agentic engineering and complex reasoning tasks. With significantly stronger coding capabilities than its predecessor, GLM-5.1 achieves state-of-the-art performance on SWE-Bench Pro and demonstrates exceptional gains across real-world software engineering benchmarks.
The most exciting news: GLM-5.1 is coming soon to Qubrid AI, making this cutting-edge model accessible to developers and enterprises who need production-ready agentic capabilities.
🚀 GLM-5.1 will be live on Qubrid AI in the coming weeks. Early access starting soon, stay tuned!
In this guide, we'll explore what GLM-5.1 is, its architecture, benchmark performance, key capabilities, and what to expect when it launches on Qubrid AI.
What is GLM-5.1?
GLM-5.1 is Z.ai's latest flagship model, designed for long-horizon tasks that can work continuously and autonomously on a single task for up to 8 hours, completing the full loop from planning and execution to iterative optimization and delivering production-grade results.
Unlike traditional LLMs that hit a performance ceiling after dozens of tool calls, GLM-5.1 is designed to break the pattern where most AI models make fast early progress on a coding problem, plateau, and then produce diminishing returns no matter how much time you give them.
GLM-5.1 is built specifically for agentic engineering:
Sustained autonomous execution - Works for up to 8 hours without human intervention on complex tasks
Advanced coding capabilities - Designed for real-world software engineering workflows, debugging, and large codebase modification
Extended agentic reasoning - Maintains goal alignment over extended execution, reducing strategy drift and error accumulation
Real-world tool integration - Terminal commands, API interactions, multi-step workflows, and complex debugging
Open-Source and Production-Ready
GLM-5.1 is available with open weights under the MIT License, meaning you can run GLM-5.1 locally, fine-tune it, and deploy it in your own infrastructure without any usage restrictions. The model weights are publicly available on Hugging Face, making it accessible to developers and enterprises worldwide.
Technical Specifications
GLM-5.1 is a 744B parameter Mixture-of-Experts model with a sparse structure that activates only the top 8 out of 256 experts, maintaining ~5.9% sparsity for hyper-efficient inference while activating only 40-44B parameters per inference. This architecture balances raw intellectual capability with practical deployment efficiency.
Key architectural features include:
200K token context window - Essential for accumulating tool call history, code files, test outputs, and error logs across extended iterations
DeepSeek Sparse Attention (DSA) - Dramatically reduces computational memory costs while preserving long-context capacity
Up to 128K output tokens - Enables whole-codebase analysis and complex refactoring tasks
Architecture Overview
GLM-5.1 leverages a Mixture-of-Experts (MoE) Transformer architecture that enables efficient scaling and specialization. At its core, the model features a sparse structure with 256 total experts, selectively activating only the top-8 experts per token processing, achieving 5.9% sparsity while maintaining exceptional reasoning and coding capabilities.
Input Prompt
│
Routing Network
│
Select Top-8 Experts (out of 256)
│
Process Through Selected Experts
│
Combine Expert Outputs
│
Generate Response
Architecture Innovations
Sparse Expert Selection: Instead of activating all parameters for every token, GLM-5.1's routing network intelligently selects which experts handle each token. This sparse structure allows:
40-44B parameters activate during inference
744B total parameters available across specialized experts
Minimal computational overhead despite enormous model scale
DeepSeek Sparse Attention (DSA): Integrated DSA mechanism dramatically reduces computational memory costs even when tracking long contexts, enabling the model to maintain 200K token context windows without excessive GPU memory overhead.
Why Mixture-of-Experts for GLM-5.1?
The MoE architecture provides several key advantages:
Benefit | Impact |
|---|---|
Efficient Parameter Scaling | 744B total parameters with only 40-44B active per token enables frontier-level performance at practical computational cost |
Expert Specialization | Different experts develop expertise in coding, reasoning, tool use, mathematical domains, and debugging |
Faster Inference | Only a fraction of parameters activate per token, enabling practical deployment and reduced latency |
Long-Horizon Agentic Tasks | Architecture supports extended reasoning chains, hundreds of tool calls, and 8-hour autonomous execution without degradation |
Efficient Context Handling | DSA integration reduces memory requirements for 200K token contexts, critical for accumulating iteration history |
This design allows GLM-5.1 to combine the power of a massive model with the efficiency needed for production deployments at scale.
Benchmark Performance: SWE-Bench Pro and Beyond
GLM-5.1 delivers exceptional performance across the benchmarks that matter most for agentic engineering:
🏆 Top Performance on SWE-Bench Pro
GLM-5.1 achieves state-of-the-art performance on SWE-Bench Pro with a score of 58.4, leading the field in real-world software engineering task resolution. This benchmark measures the model's ability to understand complex codebases, identify bugs, and implement fixes exactly what production agentic systems require.
Coding & Software Engineering Benchmarks
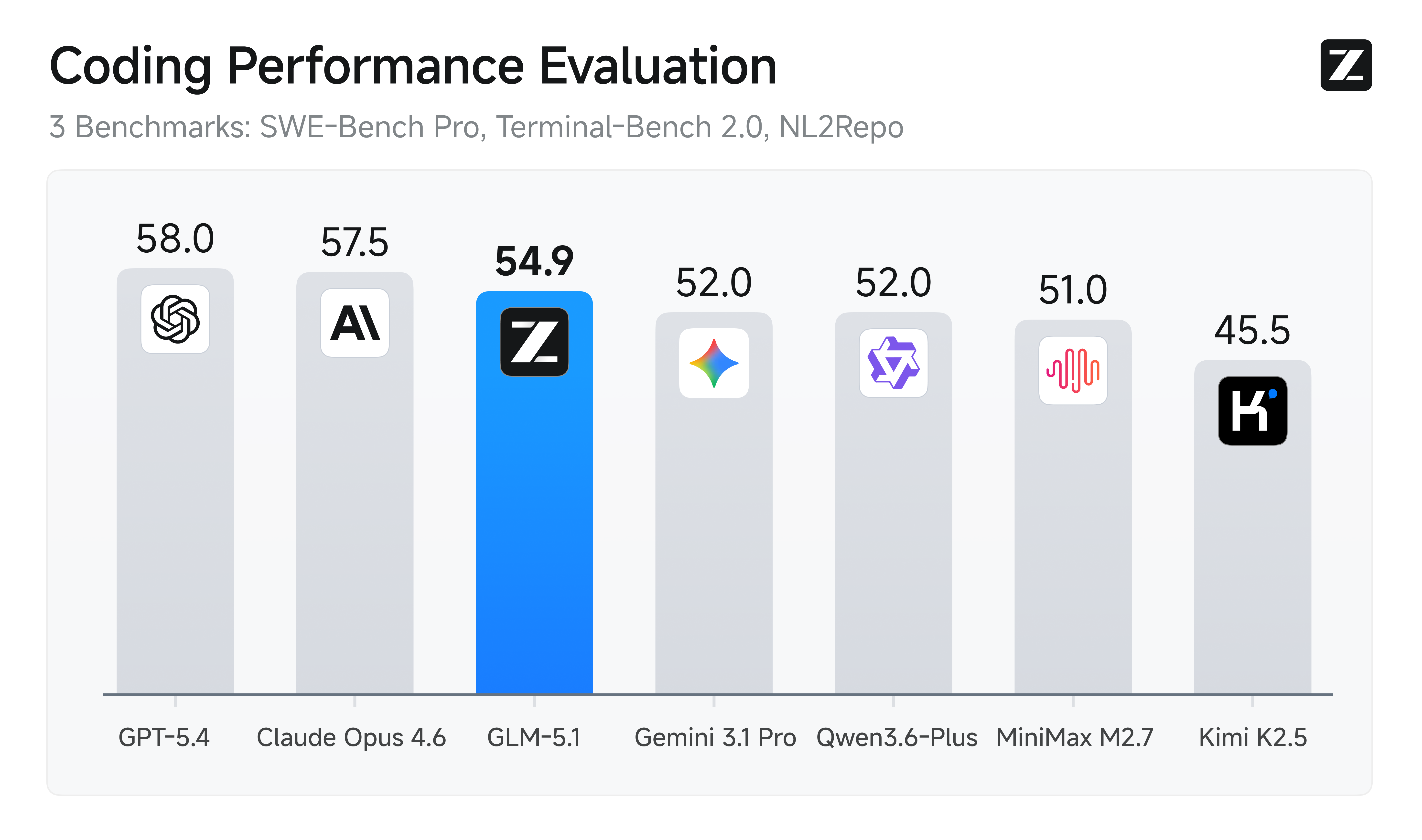
GLM-5.1 demonstrates exceptional strength in coding-specific benchmarks:
Benchmark | GLM-5.1 Score | Category | What It Measures |
|---|---|---|---|
SWE-Bench Pro | 58.4 ⭐ | Software Engineering | Real-world GitHub issues resolution and codebase modification |
NL2Repo | 42.7 | Code Generation | Repository-level code generation from natural language descriptions |
Terminal-Bench 2.0 | 63.5 | System Interaction | Terminal command execution, scripting, and system manipulation |
CyberGym | 68.7 | Security/Coding | Cybersecurity-focused agentic coding tasks |
BrowseComp | 68.0 | Web Integration | Web browsing combined with coding and information retrieval |
LiveCodeBench | Competitive | Real-time Coding | Live coding problem solving and implementation |
Advanced Reasoning & Foundation Benchmarks
Beyond coding, GLM-5.1 maintains excellence across broader intellectual benchmarks:
Benchmark | GLM-5.1 Score | Category | What It Measures |
|---|---|---|---|
AIME 2026 | 95.3 | Mathematical | Advanced mathematical reasoning and problem-solving |
GPQA-Diamond | 86.2 | Knowledge | Graduate-level questions in science and medicine |
HLE (w/ Tools) | 52.3 | Extended Reasoning | Long-horizon reasoning with external tool usage |
τ³-Bench | 70.6 | Multi-step Tasks | Complex multi-step reasoning and planning |
Tool-Decathlon | 40.7 | Tool Integration | Diverse tool usage in varied problem domains |
Why These Benchmarks Matter
SWE-Bench Pro is the gold standard for evaluating real-world software engineering capabilities. GLM-5.1's 58.4 score is industry-leading, meaning it can:
Parse and understand complex GitHub issues
Navigate large, unfamiliar codebases
Identify exact locations requiring changes
Implement fixes that pass test suites
Handle multi-file modifications and dependencies
The combination of strong coding benchmarks (SWE-Bench, NL2Repo, Terminal-Bench) with reasoning benchmarks (AIME, GPQA) shows that GLM-5.1 isn't just good at code it's built on a foundation of superior reasoning that powers its agentic capabilities.
Comprehensive Benchmark Results
The model demonstrates exceptional capability in agentic tasks, handling ambiguous problems with better judgment and remaining productive over longer sessions, making it ideal for autonomous agents that need to persist and iterate toward solutions.
Key Capabilities
1. 8-Hour Autonomous Execution
What truly sets GLM-5.1 apart is its ability to sustain optimization over extended horizons. Unlike models that plateau after dozens of tool calls, GLM-5.1 can work autonomously for up to 8 hours on a single task.
This means:
Full development lifecycle - From initial ideas to fully built applications, GLM-5.1 runs the entire process: planning architecture, building backend and frontend systems, writing tests, handling documentation, security, databases, and production configurations
Complex bug resolution - When facing intricate bugs in large systems, GLM-5.1 persistently traces problems (race conditions, memory leaks, architectural issues) and applies fixes based on careful testing
Iterative refinement - The model maintains goal alignment over extended execution, reducing strategy drift, error accumulation, and ineffective trial-and-error
Sustained productivity - While other models exhaust their techniques early, GLM-5.1 continues to improve its approach through hundreds of rounds and thousands of tool calls
This capability fundamentally changes the software development lifecycle by enabling true autonomous agents that don't need constant human oversight.
2. Superior Coding Performance on Real-World Tasks
GLM-5.1's coding capabilities go far beyond simple code generation:
Codebase understanding - Navigate and modify large, complex repositories with understanding of architecture and dependencies
Debugging with precision - Identify root causes in production codebases and implement targeted, tested fixes
Multi-file modifications - Handle changes that span multiple files while maintaining consistency and passing test suites
Real-world GitHub workflows - Parse and implement solutions for actual GitHub issues and pull requests
SWE-Bench Pro leadership - Achieves state-of-the-art 58.4 on the gold-standard benchmark for real-world software engineering
3. Extended Agentic Reasoning
GLM-5.1 sustains reasoning and optimization across hundreds of iterations:
Iterative strategy refinement - Revisits reasoning, adjusts strategies mid-task, and learns from failed attempts
Structured problem decomposition - Breaks down complex challenges into manageable steps with clear planning
Experimental validation - Tests approaches, interprets results, and learns from outcomes
Tool-call chaining - Makes precise decisions between and after tool calls through step-by-step thinking
Closed-loop optimization - Continuously improves solutions through feedback loops and self-correction
4. Real-World Tool Integration
GLM-5.1 seamlessly integrates with external tools and systems required for production work:
Terminal execution - Running system commands, interpreting output, and chaining terminal operations
API interactions - Making HTTP requests, parsing complex responses, and chaining API calls intelligently
File and repository management - Creating, modifying, analyzing, and refactoring code artifacts
Testing frameworks - Running test suites, interpreting failures, and debugging test results
Version control workflows - Managing git operations, commits, branches, and merge workflows
GLM-5.1 Coming Soon to Qubrid AI
GLM-5.1 will be live on Qubrid AI in the coming weeks. This is your chance to get immediate access to the industry's top-performing agentic model for software engineering.
When GLM-5.1 launches on Qubrid AI, you'll be able to:
Try GLM-5.1 in the Qubrid AI Playground - Test the model with free tokens before deploying
Integrate via API - Use GLM-5.1's advanced agentic capabilities in your applications with simple API calls
Deploy at scale - Leverage Qubrid's GPU infrastructure for production-grade inference
Benefit from optimized pricing - Cost-effective deployment without sacrificing performance
Why Developers Choose Qubrid AI for Cutting-Edge Models
Qubrid AI consistently brings the latest, most powerful models to market with production-ready infrastructure:
Early access - Cutting-edge models like GLM-5.1 available immediately upon release
Optimized deployment - GPU infrastructure and software stack tuned for inference efficiency
Developer-first platform - Playground, API, and documentation designed for rapid experimentation
Transparent pricing - Clear, cost-effective billing without hidden fees
Enterprise support - Dedicated assistance for larger deployments and custom requirements
Our Thoughts
GLM-5.1 represents a significant leap forward in agentic AI. The model's state-of-the-art performance on SWE-Bench Pro combined with its ability to sustain optimization over extended horizons makes it a game-changer for software engineering workflows.
The shift from "quick wins that plateau" to "continuous refinement over hundreds of iterations" is exactly what production agentic systems need. Whether you're automating codebase migrations, building autonomous debugging agents, or orchestrating complex development workflows, GLM-5.1 delivers the reasoning depth and coding precision that matter in real-world scenarios.
With GLM-5.1 coming to Qubrid AI soon, developers will have immediate access to one of the most capable agentic models available, backed by infrastructure and support designed for production use.
Ready to explore GLM-5.1?
Keep an eye on the Qubrid AI platform for the official launch announcement. In the meantime, you can explore other state-of-the-art models available today:
👉 Get Started on Qubrid AI
📚 View Complete Model Catalog
💬 Join Our Community