
How to Run Kimi K3 on Hermes Agent
Run Moonshot AI's Kimi K3 inside Hermes Agent using Qubrid's OpenAI-compatible API. Full setup, code examples, pricing ($3/M input), and vision support. Live in 10 minutes
13 min read
Read More Stay updated with the latest news and insights from Qubrid AI.

Run Moonshot AI's Kimi K3 inside Hermes Agent using Qubrid's OpenAI-compatible API. Full setup, code examples, pricing ($3/M input), and vision support. Live in 10 minutes

Moonshot AI just launched Kimi K3, and it is a big one. Literally. At 2.8 trillion parameters, K3 is the largest open model ever released, and it ships with a 1 million token context window, native visual understanding, and always-on reasoning.

Grok 4.5 launched at $2/$6 per million tokens. xAI's own charts show open-source GLM-5.2 just 2.6 points behind on SWE Bench Pro. Full comparison inside.

Qubrid AI is now officially listed on the Dify Marketplace, giving Dify's developer community direct, OpenAI-compatible access to Qubrid's model catalog inside any chat app, agent, or workflow. No custom integration, no separate infrastructure to stand up. Install the plugin, connect an API key, and Qubrid's models are available wherever Dify builds.
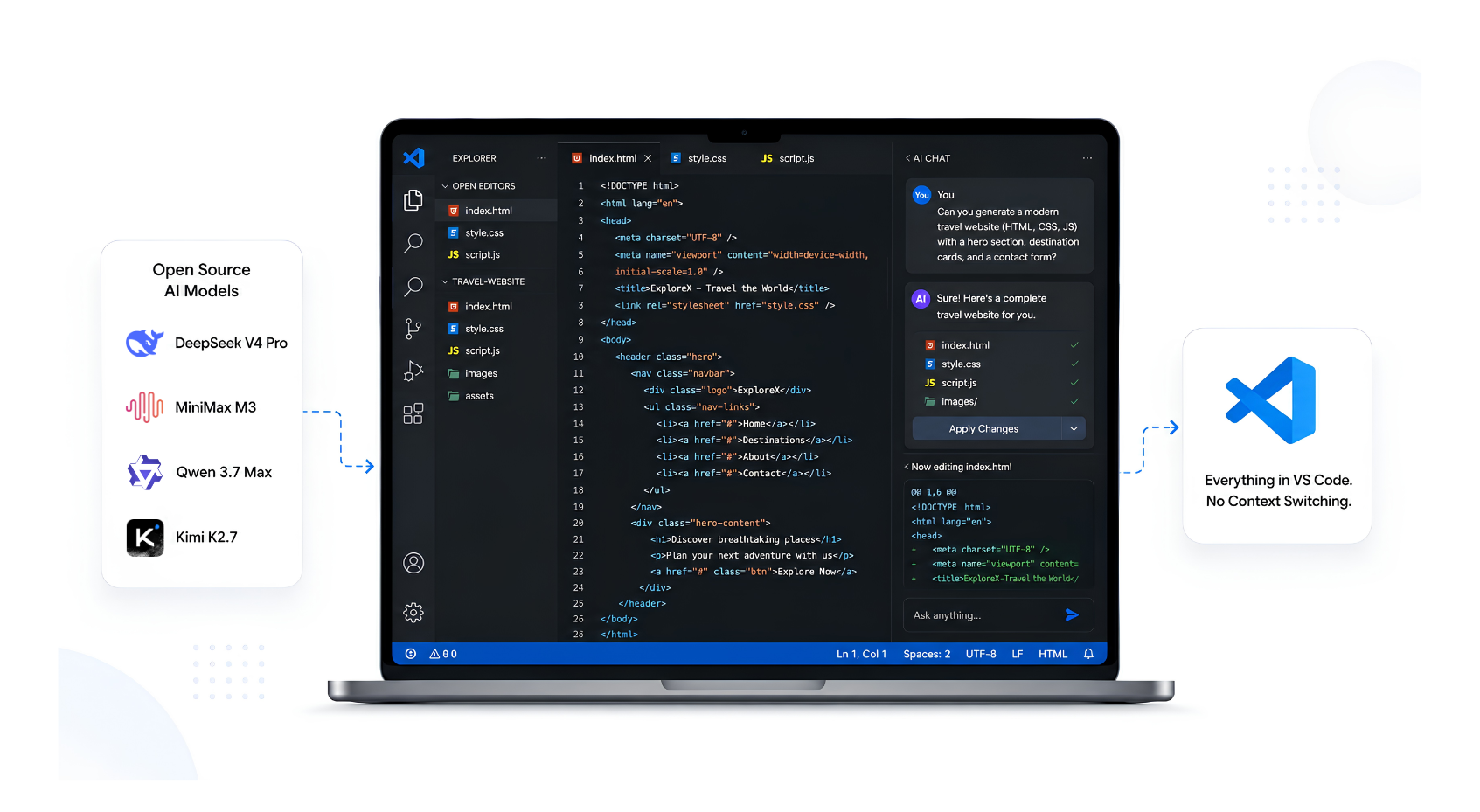
Stop context-switching between your editor and AI chat tools. Here's how to run open source models like GLM-5.2, DeepSeek, and Llama 4 natively inside VS Code using Qubrid's inference API
Official announcements from Qubrid AI

Qubrid AI, a leading Open, Inference-First Full-Stack AI Platform company, today at NVIDIA GTC 2026 announced the addition and acceleration of over forty open-source models powered by NVIDIA AI infrastructure. Enterprise agent developers can simply integrate a single API provided by Qubrid and inference over forty models from within their agentic application, decide which model suits their requirements and then scale using NVIDIA GPU VMs or dedicated GPU servers all running on Qubrid's advanced AI platform.

GLM-5.2 just claimed the top spot among open-weights models, beating GPT-5.5 on coding benchmarks, matching Claude Opus 4.8 on long-horizon tasks, and doing it all at a fraction of the cost. Qubrid AI is a Day 0 launch partner with Z.ai - which means you can build with it right now.
Shubham Tribedi

The open-source coding race just lapped the closed frontier on price. Here's how to pick your model
Shubham Tribedi

One prompt. Up to four models. Real-time responses, latency, cost, throughput - everything you need to make the right AI decision, finally in one place.
Shubham Tribedi

How to wire up Hermes Agent to production-grade inference in under five minutes - with full model control, transparent costs, and zero lock-in.
Shubham Tribedi

Alibaba's multimodal agent model - vision, deep reasoning, GUI automation, and code generation unified in a single loop - is live on Qubrid AI today.
Shubham Tribedi

The first open-weight model to combine frontier coding, million-token context, and native multimodality just launched - and you can access it right now.
Shubham Tribedi

Comparing Qwen 3.7 Max and Claude Opus 4.7 across software engineering, AI agents, long-context reasoning, benchmark performance, and API costs.
Shubham Tribedi

One of the strongest frontier models for coding agents, MCP workflows, and long-horizon AI execution is now available on Qubrid AI.
Shubham Tribedi

As open-weight models, inference optimization, and GPU infrastructure evolve rapidly, organizations are beginning to rethink where AI workloads should actually run. This deep technical analysis explores the real economics, performance tradeoffs, latency considerations, and architectural shifts driving the rise of hybrid AI systems across local, cloud, and on-prem deployments.
Shubham Tribedi

From low-latency voice assistants and streaming multimodal systems to the future of conversational infrastructure, here’s why GPT-Realtime-2 is becoming one of the most discussed topics among developers, startups, and the broader AI community
Shubham Tribedi

If you've been following the open-source LLM space over the past few months, you already know that Moonshot AI has been one of the more interesting players to watch. Their latest release, Kimi K2.6, is generating real attention among developers, and not just because of the benchmark numbers.
Shubham Tribedi

DeepSeek V4 Pro API Explained in Depth: Intelligence Scores, Token Usage, Latency, Pricing, and How to Optimize It for Production
Shubham Tribedi

How Chaitanya Bharathi Institute of Technology scaled advanced clinical image classification using NVIDIA GPUs on Qubrid AI
Have questions? Want to Partner with us? Looking for larger deployments or custom fine-tuning? Let's collaborate on the right setup for your workloads.
"Qubrid helped us turn a collection of AI scripts into structured production workflows. We now have better reliability, visibility, and control over every run."
AI Infrastructure Team
Automation & Orchestration